
This may be a long post, but I hope to keep it entertaining for both writers and non writers. Let me know what you think!
Some history – where I come from
I’ve always loved to write. As a child, I already started writing similar stories than the ones I was reading: children stories. At the time, I was left with that time’s simple tools, a pencil and pieces of paper:

Then, my father seeing that I really loved it, decided to buy me a typewriter (I unfortunately don’t have it anymore, but it was this model):

Besides the fact that it was difficult at first and hurt my fingers since the keys were so hard, it did improve the presentation of my writings by quite a bit, I even allowed myself to make ASCII art even though I didn’t know it would be called that way a decade later:

And when the occasion arose, I had to draw things myself on the paper:

I even went as far as making fake old maps to add to the mystery of the fiction I was writing:

At the time, if you wanted to know about one place where your story was taking place, you basically had to go there and get some documentation:

You could also read lots of books to get a grasp of the place, its atmosphere, its inhabitants and culture, etc. You had to be a real detective.
Then my parents decided that it was time for me to have a computer, 
This thing was top notch at the time, it had no hard disk and everything had to be on floppy disks which weren’t so reliable. It was a great improvement on the typewriter, though, and soon MSDOS had no secrets for me. I added a 20 Mb (yes, megabytes) hard disk later which cost me an arm and a leg at the time… I could use Word 2.0 to write, it was great. You could FIX things without typing back a full page! And then, PRINT it and write gibberish on it as much as you wanted to!

Great times. Believe it or not, I still have the files for these books.
Since then, and that’s like 30 years now, nothing much has changed when it comes to the comfort of writing. Of course, you can now travel the world from your desk by watching videos and reading traveler blogs, there is more material around than you can handle anyway.
But the writing, technically? Good ol’ Word. Ah, Libre Office has come around so that you don’t depend on a private company anymore, but that’s pretty much all there is to it.
Of course, in the more recent years, self-publishing has enabled anyone to publish books, while publishing anything was practically impossible before unless an editor accepted to support you.
Tools and Constraints
There are some tools for professional writers. I won’t quote them here because I don’t want to rant, but the added value doesn’t compensate for their price, at least that’s my own opinion.
As a writer, I have quite a number of needs in order to write efficiently:
- describe the characters in my story, have their personality and picture at hand whenever I need it,
- describe the places where my story happens, possibly along with pictures, maps or drawings,
- dynamically design the plot in the most flexible way possible, by quickly arranging events and/or themes seamlessly,
- have an overview of the entire book the whole time to see where I stand,
- count words inside chapters to make sure they are roughly balanced (Word documents count the total words of the document, they don’t break the counts into chapters),
- handling of Table of Contents, presentation of the book, references, footnotes, etc., should be easy and not troublesome, in fact you should never even think about those as it would distract you from writing,
- navigate efficiently through the book with shortcuts rather than having to scroll pages and pages to reach one chapter,
- have the finished product in the form of an epub and various pdf formats (one for reading on a screen, one for a small paperback edition with small characters and at least one for a big paperback edition for people with poor vision),
- manage to have a history of changes.
Frankly, none of the current software can deal with all these constraints easily. Word/LibreOffice documents are a nightmare. LaTeX constantly distracts you from the contents and doesn’t provide an easy way to navigate through the whole document (I wrote my PhD using LaTeX).
Mind Maps are the Perfect Tool
In the meantime, as a computer engineer, I started using Mind Maps at work to organize ideas. Scientific, computer-related ideas.
If you don’t know what a Mind Map is, it’s just a simple tree of ideas such as this:

You organize your ideas in nodes which are broken into smaller nodes as you refine your ideas. These are great for technical planning and thinking.
Some day, I started planning a new book inside a mind map. Just to draw the basic canvas of the story. Then I added my characters into it.
The main plot was in front of me, the characters next to it. Why not write the book inside the mind map? I know that, as soon as you start breaking your ideas into different documents, some of these documents will become out of date very quickly. By writing directly inside the mind map, I had only one document to maintain.
Most Mind Mapping software allows to type some HTML notes inside every node, that’s where I typed the main text of the book. And because it’s HTML, I can add images, put some formatting, bold, etc.
Converting a Mind Map to PDF and EPUB
To my knowledge, there is no converter to create a PDF or an EPUB from a Mind Map. If you think about it, a Mind Map is a simple text document that can be easily parsed, in the meantime libraries to generate PDFs exist, while an EPUB is a simple Zip file with some HTML files inside.
So I wrote a converter in Java, which also counts the number of words in every chapter and sub-chapter.
Thanks to this, I can easily:
- have everything in one place with all I need visible in one document: the characters and locations along with the basic ideas, the whole book where chapters are nodes and sub-chapters are sub-nodes, and the nodes’ contents is the text of the book itself, so it’s extremely fast and easy to navigate from one part of the book to another,
- navigate from a character to a given chapter with a simple mouse click,
- move ideas, events, plots around during the planning phase, while developing characters and locations in the same document,
- count words in every chapter and sub-chapter with my converter to make sure that things are not totally out of balance,
- have one single source file for many output formats for the readers, which are even described in the Mind Map,
- Mind Maps are text files, it is easy to compare a file with a previous backup to see what has changed.
Here is an example of a test mind map that is later transformed into a book (nodes with a yellow icon have notes typed into them):
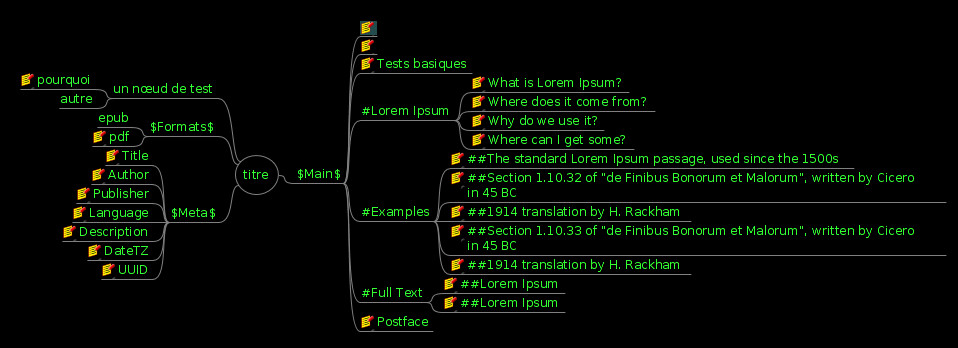
The generated PDF looks like this:

And the generated Epub is readable on any reader, uploadable to any self-publishing platform.
I hope this converter can help other people as well. Note that its current version as I write this article is rather limited but is perfectly suitable for a simple novel. Its limitations are listed in the description of the tool itself on gitlab.
Did you like this? Let me know in the comments below!
















