

The post title may be blunt. But I think after reading this article, you will never use the type “char” in Java ever again.
The origin of type “char”
At the beginning, everything was ASCII, and every character on a computer could be encoded with 7 bits. While this is fine for most English texts and can also suit most European languages if you strip the accents, it definitely has its limitations. So the extended character table came, bringing a full new range of characters to ASCII, including the infamous character 255, which looks like a space, but is not a space. And code pages were defining how to show any character between 128 and 255, to allow for different scripts and languages to be printed.
Then, Unicode brought this to a brand new level by encoding characters on… 16 bits. This is about the time when Java came out in the mid-1990s. Thus, Java designers made the decision to encode Strings with characters encoded on 16 bits. All Java char has always been and is still encoded with 16 bits.
However, when integrating large numbers of characters, especially ideograms, the Unicode team understood 16 bits were not enough. So they added more bits and notified everyone: “starting now, we can encode a character with more than 16 bits”.
In order not to break compatibility with older programs, Java chars remained encoded with 16 bits. Instead of seeing a “char” as a single Unicode character, Java designers thought it best to keep the 16 bits encoding. They thus had to introduce the new concepts from Unicode, such as “surrogate” chars to indicate that one specific char is actually not a character, but an “extra thing”, such as an accent, which can be added to a character.
Character variations
In fact, some characters can be thought of in different ways. For instance, the letter “ç” can be considered:
- either as a full character on its own, this was the initial stance of Unicode,
- either as the character “c” on which a cedilla “¸” is applied.
Both approaches have advantages and drawbacks. The first one is generally the one used in linguistics. Even double characters are considered “a character” in some languages, such as the double l “ll” in Spanish which is considered as a letter on its own, separate from the single letter “l”.
However, this approach is obviously very greedy with individual character unique numbers: you have to assign a number to every single possible variation of a character. For someone who is only familiar with English, this might seem like a moot point. However, Vietnamese, for instance, uses many variations of those appended “thingies”. The single letter “a”, can follow all those individual variations: aàáâãặẳẵằắăậẩẫầấạả. And this goes for all other vowels as well as some consonants. Of course, the same goes for capital letters. And this is only Vietnamese.
The second approach has good virtues when it comes to transliterating text into ASCII, for instance, since transliterating becomes a simple matter of eliminating diacritics. And of course, when typing on a keyboard, you cannot possibly have one key assigned to every single variation of every character, so the second approach is a must.
Special cases: ideograms
When considering ideograms, there are also a small number of “radicals” (roughly 200 for Chinese). Those get combined together to form the large number of ideograms we know (tens of thousands).
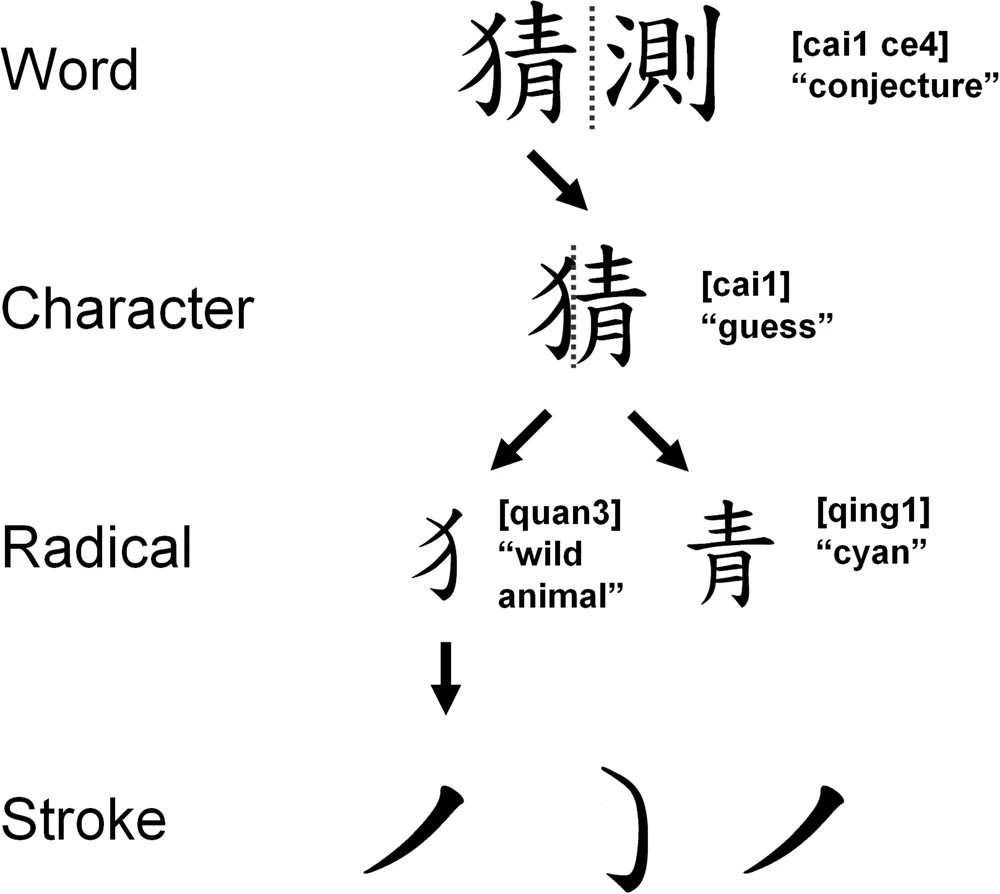
It would be feasible to represent any Chinese character using a representation using radicals and their position. However, it is more compact to list all possible Chinese characters and assign a number to each of them, which is what was done by Unicode.
Korean Hangul
Another interesting case is Hangul, which is used to write Korean. Every character is actually a combination of letters and represents a syllable:

So, in some cases, it is easier to assign a number to every individual components and then combine them (which happens when typing in Korean on a keyboard). There are only 24 letters (14 vowels and 10 consonants). However, the number of combinations to form a syllable is very large: it amounts to more than 11 000, although only about 3 000 of them produce correct Korean syllables.
Funny characters
People, especially in social media, use an increasing number of special characters, emojis, and other funny stuff, from 𝄞 to 🐻. Those have made it into Unicode, thus making it possible to write ʇxǝʇ uʍop ǝpısdn, 𝔤𝔬𝔱𝔥𝔦𝔠 𝔱𝔢𝔵𝔱, or even u̳n̳d̳e̳r̳l̳i̳n̳e̳d̳ ̳t̳e̳x̳t̳ without the need for formatting or special fonts (all the above are written without special fonts or images, those are standard Unicode characters). Every flag of the world’s countries have even made it as a single character into the Unicode norm.
This plethora of new characters which made it late into the standard are often using more than 16 bits for their encoding.
Using type “char” in Java
When using the type “char” in Java, you accept that things like diacritics or non existent characters will be thrown at you, because remember, a char is encoded with 16 bits. So, when doing “𝄞”.toCharArray() or iterating through this String’s chars, Java will throw at you two characters that don’t exist on their own:
- \uD834
- \uDD1E
Both those characters are illegal, and they only exist as a pair of characters.
Bottom line, when it comes to text, chars shouldn’t be used. Ever. In the end, as a Java developer, you have probably learned that, unless doing bit operations, you should never use String.getBytes(), and use chars instead. Well, with the new Unicode norms and the increasing use of characters above 0xFFFF, when it comes to Strings, using char is as bad as using byte.
Java type “char” will break your data
Consider this one:
System.out.println("𝄞1".indexOf("1"));
What do you think this prints? 1? Nope. It prints 2.
Here is one of the consequences of this. Try out the following code:
System.out.println("𝄞1".substring(1))
This prints the following, which might have surprised you before reading this blog post:
?1
But after reading this post, this makes sense. Sort of.
Because substring() is actually checking chars and not code points, we are actually cutting the String which is encoded this way:
\uD834 \uDD1E \u0031
\___________/ \____/
𝄞 1
It is amazing that a technology such as Java hasn’t addressed the issue in a better way than this.
Unicode “code points”
Actually, it is a direct consequence of what was done at the Unicode level. If you tried to break down the character 𝄞 into 16 bits chunks, you wouldn’t get valid characters. But this character is correctly encoded with U+1D11E. This is called a “code point”, and every entry in the Unicode character set has its own code point.
The down side is that an individual character may have several code points.
Indeed, the character “á” can be either of these:
- the Unicode letter “á” on its own, encoded with U+00E1,
- the Unicode combination of the letter “a” and its diacritic “◌́”, which results in the combination of U+0061 and U+0301.
Java code points instead of char
A code point in Java is a simple “int”, which corresponds to the Unicode value assigned to the character.
So when dealing with text, you should never use “char”, but “code points” instead. Rather than
“a String”.toCharArray()
use
“a String”.codePoints()
Instead of iterating on chars, iterate on code points. Whenever you want to check for upper case characters, digits or anything else, never use the char-based methods of class Character or String. Always use the code point counterparts.
Note that this code will actually fail with some Unicode characters:
for (int i = 0 ; i < string.length() ; i++)
if (Character.isUpperCase(string.charAt(i)))
... do something
This will iterate through characters that are NOT characters, but Unicode “code units” which are possibly… garbage.
Inserting data into a database
Consider a simple relational table to store unique characters:
| Charac | |
| id 🔑 (primary key) | int(11) |
| c (unique constraint) | varchar(4) |
Now imagine your java program is inserting unique characters in the column “c” of this table. If based on “char” the Java program will consider two different surrogate chars as different since their code are different, but the database will store strange things at some point since those are not valid Unicode codes. And the unique constraint will kick in, crashing your program, and possibly allowing wrong Unicode codes to be pushed into the table.
Alternative replacements
| String.toCharArray() | String.codePoints() (to which you can append toArray() to get an int[]) |
| String.charAt(pos) | String.codePointAt(pos) |
| String.indexOf(int/char) | String.indexOf(String) |
| iterate with String.length() | convert String into an int[] of code points and iterate on those |
| String.substring() | Make sure you don’t cut between a surrogate pair. Or use int[] of code points altogether. |
| replace(char, char) | replaceAll(String, String) and other replace methods using Strings |
|
new String(char[]) |
new String(int[] codePoints, int offset, int count) with code points |
| Character methods using type char | Character methods using int code points |