
Première vidéo d’une série sur la blockchain. Si vous avez entendu parler de cette technologie mais que vous vous posez des tas de questions, cette série est faite pour vous !
Visible aussi sur youtube : https://www.youtube.com/watch?v=6xOyBMkRcHQ
Jean-Yves Toumit

Première vidéo d’une série sur la blockchain. Si vous avez entendu parler de cette technologie mais que vous vous posez des tas de questions, cette série est faite pour vous !
Visible aussi sur youtube : https://www.youtube.com/watch?v=6xOyBMkRcHQ
This may be a long post, but I hope to keep it entertaining for both writers and non writers. Let me know what you think!
I’ve always loved to write. As a child, I already started writing similar stories than the ones I was reading: children stories. At the time, I was left with that time’s simple tools, a pencil and pieces of paper:

Then, my father seeing that I really loved it, decided to buy me a typewriter (I unfortunately don’t have it anymore, but it was this model):

Besides the fact that it was difficult at first and hurt my fingers since the keys were so hard, it did improve the presentation of my writings by quite a bit, I even allowed myself to make ASCII art even though I didn’t know it would be called that way a decade later:

And when the occasion arose, I had to draw things myself on the paper:

I even went as far as making fake old maps to add to the mystery of the fiction I was writing:

At the time, if you wanted to know about one place where your story was taking place, you basically had to go there and get some documentation:

You could also read lots of books to get a grasp of the place, its atmosphere, its inhabitants and culture, etc. You had to be a real detective.
Then my parents decided that it was time for me to have a computer, 
This thing was top notch at the time, it had no hard disk and everything had to be on floppy disks which weren’t so reliable. It was a great improvement on the typewriter, though, and soon MSDOS had no secrets for me. I added a 20 Mb (yes, megabytes) hard disk later which cost me an arm and a leg at the time… I could use Word 2.0 to write, it was great. You could FIX things without typing back a full page! And then, PRINT it and write gibberish on it as much as you wanted to!

Great times. Believe it or not, I still have the files for these books.
Since then, and that’s like 30 years now, nothing much has changed when it comes to the comfort of writing. Of course, you can now travel the world from your desk by watching videos and reading traveler blogs, there is more material around than you can handle anyway.
But the writing, technically? Good ol’ Word. Ah, Libre Office has come around so that you don’t depend on a private company anymore, but that’s pretty much all there is to it.
Of course, in the more recent years, self-publishing has enabled anyone to publish books, while publishing anything was practically impossible before unless an editor accepted to support you.
There are some tools for professional writers. I won’t quote them here because I don’t want to rant, but the added value doesn’t compensate for their price, at least that’s my own opinion.
As a writer, I have quite a number of needs in order to write efficiently:
Frankly, none of the current software can deal with all these constraints easily. Word/LibreOffice documents are a nightmare. LaTeX constantly distracts you from the contents and doesn’t provide an easy way to navigate through the whole document (I wrote my PhD using LaTeX).
In the meantime, as a computer engineer, I started using Mind Maps at work to organize ideas. Scientific, computer-related ideas.
If you don’t know what a Mind Map is, it’s just a simple tree of ideas such as this:

You organize your ideas in nodes which are broken into smaller nodes as you refine your ideas. These are great for technical planning and thinking.
Some day, I started planning a new book inside a mind map. Just to draw the basic canvas of the story. Then I added my characters into it.
The main plot was in front of me, the characters next to it. Why not write the book inside the mind map? I know that, as soon as you start breaking your ideas into different documents, some of these documents will become out of date very quickly. By writing directly inside the mind map, I had only one document to maintain.
Most Mind Mapping software allows to type some HTML notes inside every node, that’s where I typed the main text of the book. And because it’s HTML, I can add images, put some formatting, bold, etc.
To my knowledge, there is no converter to create a PDF or an EPUB from a Mind Map. If you think about it, a Mind Map is a simple text document that can be easily parsed, in the meantime libraries to generate PDFs exist, while an EPUB is a simple Zip file with some HTML files inside.
So I wrote a converter in Java, which also counts the number of words in every chapter and sub-chapter.
Thanks to this, I can easily:
Here is an example of a test mind map that is later transformed into a book (nodes with a yellow icon have notes typed into them):
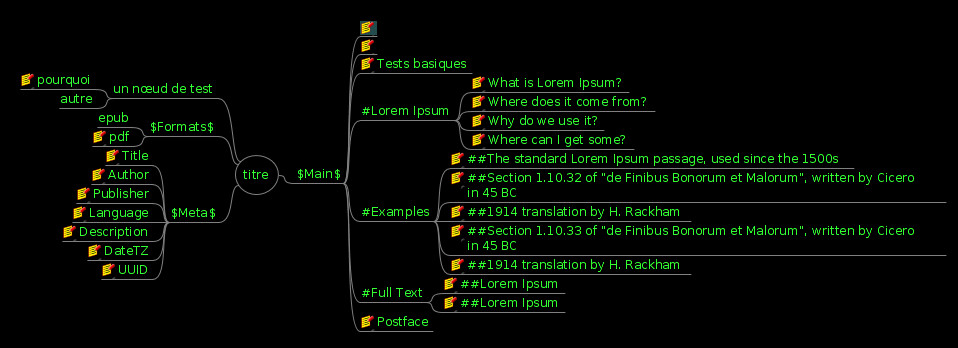
The generated PDF looks like this:

And the generated Epub is readable on any reader, uploadable to any self-publishing platform.
I hope this converter can help other people as well. Note that its current version as I write this article is rather limited but is perfectly suitable for a simple novel. Its limitations are listed in the description of the tool itself on gitlab.
Did you like this? Let me know in the comments below!
In this digital era, we all have data that we care about. You certainly wouldn’t want to lose most of your earliest baby pictures. 😀

That data is very diverse, both in its nature and in its dynamism. You have static backups such as your baby pictures, but also very dynamic data such as your latest novel. You also have a lot of data that you probably don’t want to back up at all, such as downloaded files and programs. Well, if those files are actually your bank statements, you may want to have a backup in case something goes awfully wrong.
Many people store their “stuff” on their computer, and that’s about it. Then one day, the computer crashes. Bad news, the hard disk is dead. Woops.
The thing is, hard disks fail. In 30 years of dealing with computers on a daily basis, I’ve experienced on average one hard disk failure every 2 years, and I don’t even mention the countless floppy disks that died in my hands. 😀 Maybe I’m unlucky. Maybe I use computers too much.
Regardless, I know people around me who also experienced hard disk failures and were not prepared for them. Some of them took it well, invoking destiny, others didn’t take it so well. But in any case, when it comes to data loss, destiny can be bent. And although I’ve had mostly hard drive failures, SSDs fail too, and in an even worse way since they generally give very little warning signs (if any) and the whole disk is gone at once, whereas on traditional hard drives it may still be possible to retrieve some of the data. USB keys and SD cards are no exceptions, I’ve found they fail quite often, even the ones from established brands.
Most of the time, trained and highly skilled professionals can recover most of the data using specialized equipment. For some examples of what is possible, you can check out this video channel of a very talented data recovery expert for amazing videos. But that comes at a cost. And recovering everything is not always possible.
The good thing about computers is that, unlike paper data, digital stuff can be copied over and over, and that process is very easy and lossless. You just need to use this capability!
The first step towards minimizing the risk of losing data because of a hard disk failure is to set up a RAID (Redundant Array of Independent Disks). The basic idea is to spread your data and duplicate it on several disks, so that if one fails, your data is still on the other disks and you have cheated destiny. We will cover that in the second part of this series.
But keep this motto in mind: “Redundancy Is Not A Backup”. You have your array of disks and you can be sure now that even if one hard disk fails, you are still safe. Now, what if a second hard disk fails just after that? What if a power surge fries all your disks? Hardware failures happen, sometimes of something else (motherboard, SATA controller, etc) that even corrupts your data like it happened to this guy. Viruses encrypt all your data and ask for a 1 million $ ransom to get it back. Human error is always possible and you may mistakenly delete some important files. What if your apartment gets robbed? What if it burns or gets flooded? And yes, it even happens to the best!
This is why, along with redundancy, you always NEED backups. You should obviously not store them anywhere near your computer, ideally not even in your home in case something bad happens there. We’ll get into more detail about this in the third part of this series.
Last but not least, as soon as you store your backups outside of your home, then comes the problem of privacy: what if someone comes across your backup and gets access to your data? You may not care about some of it being accessed by strangers, but you will probably want to shield some of your precious files from prying eyes. That will be the fourth and last part of this series.
If you haven’t read the previous parts, you should start at part 1.
Now that we have a Neural Network architecture and a Genetic Algorithm, we can apply them to the game “Einstein Würfelt Nicht”.
There are several parameters that need to be addressed first:
There are some precedents for every of these 3 points (NNs as well as GAs have been studied), but there is no existing answer for this particular set of problems.
The answer to the first question seems trivial, but it is actually not. The first answer that comes to mind is “just feed it the board and the die and get the stone that has to be played and the move to be played”.
This is of course a valid answer, but there are many more:
There are many other ways of feeding information, including feeding redundant information. For instance, you could feed the number of stones left for each player in addition to the board: that’s an information which is obviously useful and that the network could directly use rather than having to calculate it again.
The Neural Network can be used to gather very different results, also depending on which information it was given as inputs. Here are a few ways that the network can be used:
Again, there are many ways of using a neural network to play. We could even use two networks: one to choose the tile to play, and then a second one to choose the move. Whatever we choose, we have to keep in mind two main points here:
I tend to reason in terms of complexity of the game to address this problem. Just think about “if I had to code a perfect player for this game, how many rules and cases would I have to take into account”.
The answer also depends on what you feed the network. If you feed it a lot of redundant information (for instance, feed it the board and the number of remaining tiles for each player), then the network will have to extract less metadata from the board.
In the case of the game “Einstein Würfelt Nicht”, I chose not to mostly not give any redundant information to the network. Given the size of the board, I believed that a simple network of just a few layers and a couple of hundred neurons would probably do the trick.
Then comes the number of connections between layers. In order to extract as much information as possible from the board, I believed that a fully connected first layer was needed – although I chose not to enforce it, but I gave a sufficient amount of connections for this to happen. So I started off with a first layer of 20 neurons, along with 500 connections between the board (which is a 25 bytes array, with an additional byte for the die). I have also tried other different variants.
I started off with a population of 100 individuals and made some tests with 200. In that population, I chose to keep a fair amount of the best individuals, 10 to 30%, without checking their scores. All the others are discarded and replaced with either new individuals, either top individuals that have been mutated and crossed-over.
As for the mutation rate, I made it randomly chosen between 1/1000 and ten to twenty per 1000. That is to say that to create a mutated individual, 1 to 10/20 random mutations are applied for every 1000 bytes of its DNA. Note that with a network of 10000 elements, that’s just a few mutations in the network. A mutation can be a change in an operation, a connection move or a change in parameters such as weight and offset.
As for the crossover rate, I made it from 0.01% to 1%. As we will see later, it wasn’t that successful in the first versions.
Another important parameter is the accuracy of the evaluation for every individual. In the case of a game, it can be measured by having this individual play many games against other players. Other players may be other individuals of the population and/or a fixed hard-coded player. The more games are played, the more accurate the rating of a player. And this is getting more and more critical as the player improves: at the beginning, the player just needs to improve very basic skills and moves, it is failing often anyway, so it is easy to tell the difference between a good player and a bad one. As it improves, it becomes more and more difficult to find situations in which players can gain an advantage or make a slight mistake.
In the case of EWN, as it is a highly probabilistic game, the number of matches that are required can grow exponentially. Note that there are even a large number of starting positions: 6! x 6! which is roughly 500 thousand permutations. With symmetries we can remove some of them, but there is still a large number of starting positions despite the very simple placing rules. So even if you play 100.000 games for a player, it is still not covering the wide variety of openings. What if your player handles well those 100.000 openings but is totally lame at playing the rest? Not even mentioning the number of possible positions after a few turns.
A good indicator to check whether we have played enough games to correctly rate players is the “stability” of the ranking of players as we continue playing games. As the rankings stabilize (eg for instance the top player remains at the top for quite a long time) we are getting better and better accuracy.
As I developed this and started testing it, I realized that the evolution was going very slowly: new individuals were bad in general, with only a few of them reaching the “elite” of the population. That’s because of the randomness of the alterations. We will see later how I tackled that problem.
As I was going forward in this and observing how slow the process was on a CPU, I also started planning to switch the whole evaluation process to the GPU.
Welcome to this fourth part of building Neural Networks evolved by Genetic Algorithms. If you haven’t done so yet, I would advise to read the first, second and third parts before reading this article.
So, what exactly is a Genetic Algorithm? The name applied to Computer Science sounds both scary and mysterious.
However, it is actually quite simple and refers to Darwin’s theory of evolution which can be summed up in one simple sentence: “The fittest individuals in a given environment have a better chance than other individuals of surviving and having an offspring that will survive”. Additionally, the offspring carries a mutated crossover version of the genes of the parents.
Given this general definition, the transposition to Computer Science is the following:
With this in mind, the choice in part 3 to store our neural networks in simple arrays comes into a new light: those arrays are the chromosomes of our individuals.
The genetic algorithm I built went through several phases already.
Here is the first phase:
Still, with this simple algorithm, there are many possible parameters:
To evaluate the impacts of these parameters, I then built an UI on top of this to observe the evolution of the population and see how the best individuals evolve. The UI is made of a simple table, sorted by “performance” (that’s to say the percentage of wins). Every row shows one individual, its ranking, its age (since a single individual can survive for multiple generations), its original parent, and the number of total mutated generations it comes from.
Later, I also added at the bottom of the screen the progression of the score of the best individuals.
Here is a simple screenshot:

The green part represents the individuals that will be selected for the next generation. All individuals in red will be discarded. The gray ones are non NN implementations that can be used as “benchmarks” against the NN implementations. When the first population is created randomly, they are generally beaten very easily by those standard implementations, but we can see that after some iterations, the NNs selected one generation after the other end up beating those standard implementations. We’ll dig into that in the next post, along with the choice of the different parameters.
Next comes part 5.
Raspberries are awesome. But setting up things can sometimes be a little messy. I wanted to install a working version of Silkaj (see the Duniter project, if you don’t know them yet, check them out, they rock!) and here is a full tutorial to get you going.
You will need to have libsodium and libffi already installed, as well as libssl and its development package, otherwise install them:
sudo apt-get install libsodium13 libsodium-dev libffi6 libffi-dev libssl-dev
Note that you do need the development packages because python’s installer will need to compile some dependencies with them later.
Check where libffi.pc has been installed:
find /usr -name "*libffi.pc*"
You need to add the path for libffi.pc to the python environment variable PKG_CONFIG_PATH. Check if that variable is empty or not, if it’s not empty, you need to APPEND the following instead of overwriting it of course (change the location of libffi.pc to the result of your previous command):
export PKG_CONFIG_PATH=/usr/lib/arm-linux-gnueabihf/pkgconfig/libffi.pc
Because silkaj and its dependencies doesn’t run well with older versions of python, you need to install Python 3.6. Here is the recipe:
wget https://www.python.org/ftp/python/3.6.0/Python-3.6.0.tgz
tar xzvf Python-3.6.0.tgz
cd Python-3.6.0/
./configure
make
sudo make install
The following needs to be done as root or with sudo (unless you want to install for your user only):
sudo python3.6 -m pip install --upgrade pip
sudo python3.6 -m pip install pynacl
sudo python3.6 -m pip install pipenv
Type the following in your shell with any user:
git clone https://git.duniter.org/clients/python/silkaj.git
cd silkaj
pipenv install
pipenv shell
This last command actually starts a new shell in which silkaj can be run.
That’s it! You’re ready to run silkaj now:
./silkaj
Welcome to the third part of the GANN-EWN (Genetic Algorithms for Neural Networks applied to the game “Einstein Würfelt Nicht”) series! If you haven’t read it yet, it’s probably time to read the first part and/or the second part.
In this part, we’ll start building a Neural Network from scratch.
I assume that you’re familiar with Neural Networks, which are basically a simplified stereotype of what people thought neurons in the brain were like in the 1950’s. 🙂 Since then, biological research has evolved a lot and we know now that real neurons and their interactions are much more complex than the general models of Computer Neural Networks that are around.
Anyway, there are many types of neural networks around, all used for different tasks. My attempt is to build a very generic neural network structure that can then be used in various environments, typically to play different games.
Since the early days of neural network research, the transfer functions used in artificial neurons have been carefully chosen to enable backpropagation. In here, though, we want to use our neural network through Genetic Algorithms by selecting the best neural networks within a population, and we won’t necessarily be using backpropagation to make the network “learn”. So we can use any kinds of transfer functions we want.
At first, I also wondered if I would be using totally random graphs for my network structure, but it poses problems such as cycles which require more computational power to deal with so I stayed with a “simple” layer architecture. But because I wanted to code a network that would be as generic as possible, the only constraints I kept was to have a structure with layers: links between neurons of different layers can be as random as possible, with the only requirement that every neuron should have at least one input and one output (a neuron without any input or output would simply be useless and would waste resources unnecessarily). On the other hand, I didn’t put any restrictions on duplicate links from one neuron to another. After all, it could be useful to have the sinus of something and combine it with its raw value.
Another important decision was to limit to the strict minimum the manipulation of floating point values. There are two reasons for this, which are both linked to the projected use of GPUs for my research, and based on my own experience of using GPUs. The first one is that GPUs in general are not so great, performance-wise, with floating point values. The second is that the results of floating point operations may differ between CPU operations and GPU operations, due to rounding and approximating some functions on the GPU. Besides, most GPUs have limited support for double floating point operations, which makes portability some kind of a pain. We will actually discuss that in more detail in another article.
So I decided to take only integers as neuron and link input and output values, as well as the weights and shifts that could be applied on all operations. However, some operations will need some floating point numbers, such as sigmoid and tangent functions, but the results will be transformed back into integers as soon as possible so that floats are used as little as possible.
Besides, as I didn’t stick with “simple” linear or sigmoid functions for my neurons, the links themselves also have interesting properties. Here is a simple figure showing the basics of my neurons and links:
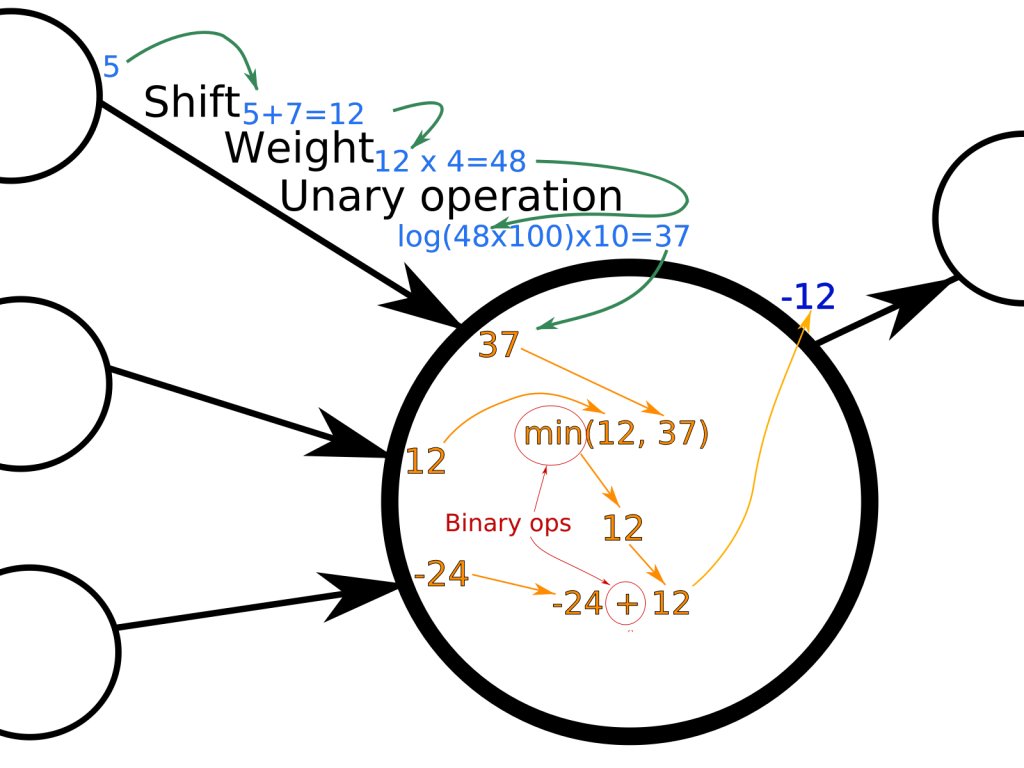
So the output of every link is of the form: out = unary_op ( (in + shift) x weight )
As for computing the result of a neuron, I used what is generally referred to as “genetic programming” where the genetic algorithm doesn’t mutates “parameters” for a program, but rather a tree of instructions (a program). So in my case, a neuron contains a tree of mathematical operations to be applied on the inputs.
So the output of a neuron having n inputs is:
For instance, the tree for the previous picture is the following:
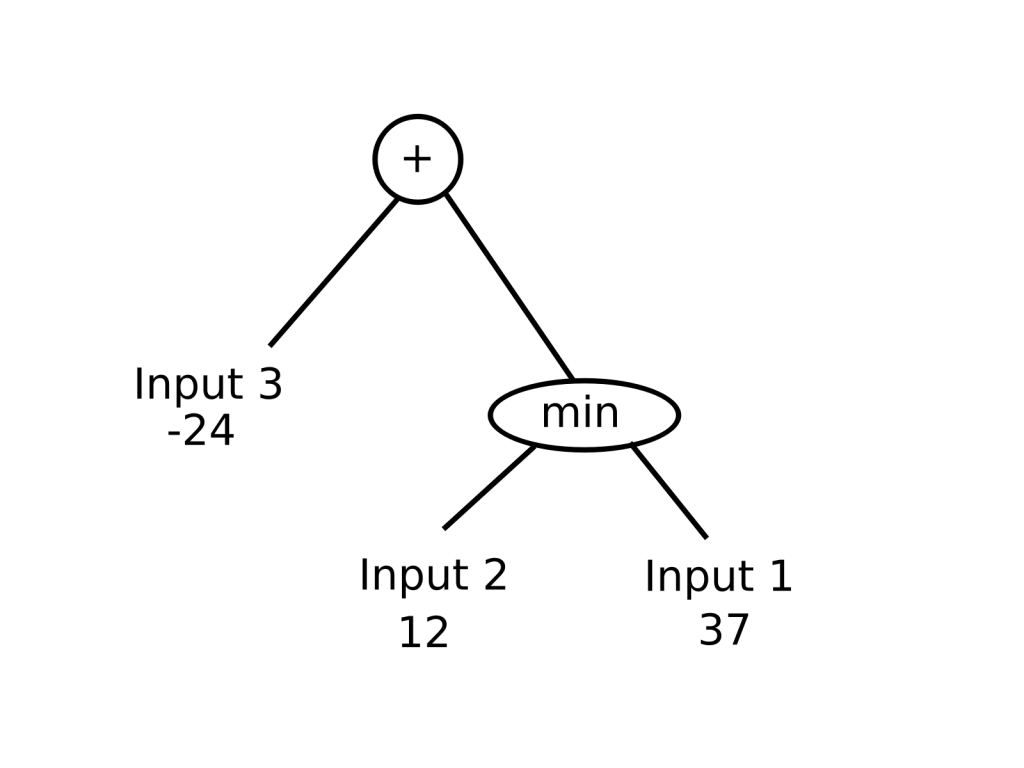
The unary operations I have chosen are: id (identity), sinus, log, square, square root, tan, and negative.
The roughly described binary operations are:
With this in mind, it is actually not difficult to switch this network to any type of network, including simple linear functions. Just limit the allowed operations to “+” and we’re pretty good to go. The same goes with links, just restrict them to use “identity” as their unary operations and set the weights as desired, just leave the offset (often called “bias” in neural network computing).
Besides, as the link structure is not constrained either, we can create any type of network we want by forcing the links to be in a certain way when we build the network.
There is one remaining problem here: if you store everything as integers and never stop adding and multiplying numbers, you’ll overflow at some point.
So I kept all operations to be within a certain range and added weights and min/max to make sure that all numbers would be kept within that range. How to define the range? It has to be as big as possible to allow for enough precision (obviously if we keep only integer values from -10 to 10, we won’t be able to store Pi using a good precision, but if we go up to a million, then we can store 3.14159, which is already not that bad). On the other hand, the range should allow not to lose precision while doing operations such as multiplying integers. Integers in Java or OpenCl have a rough range of -2 billion to 2 billion so 10.000 should do it (the square is 100 million, perfectly in range).
So within the network, all values circulating should be within the -10.000 to 10.000 range, which means that some adjustments had to be made on the different binary and unary operations, in order to always keep results within that range. For instance, adding is converted to an average, to make sure the result is still within the desired range.
Because the ultimate goal is to run this on GPUs, the networks cannot be programmed as Objects. Instead, plain arrays of integers are used. One other advantage is that it is very simple to store an array of integers and it could be manipulated in any programming language (provided that we code the program that would interpret this array).
Here is the description of the array describing a network so far:
Every link contains 5 integers and is described as follows:
Let’s calculate the size of an array needed to encode the following network: 20 connections between inputs and the first hidden layer, 10 neurons in the first hidden layer, 30 connections from the first hidden layer to the second hidden layer, 4 neurons in the second hidden layer, 10 connections from the second hidden layer to the 2 outputs.
1 + 2 x 2 + 5 x 50 + 19 + 29 = 303 elements
For now, the networks are stored within a simple local H2 database.
Finally, I built a small UI to watch how the network behaves when its inputs change. Later, it might come in handy to see how the network behaves during a real game:
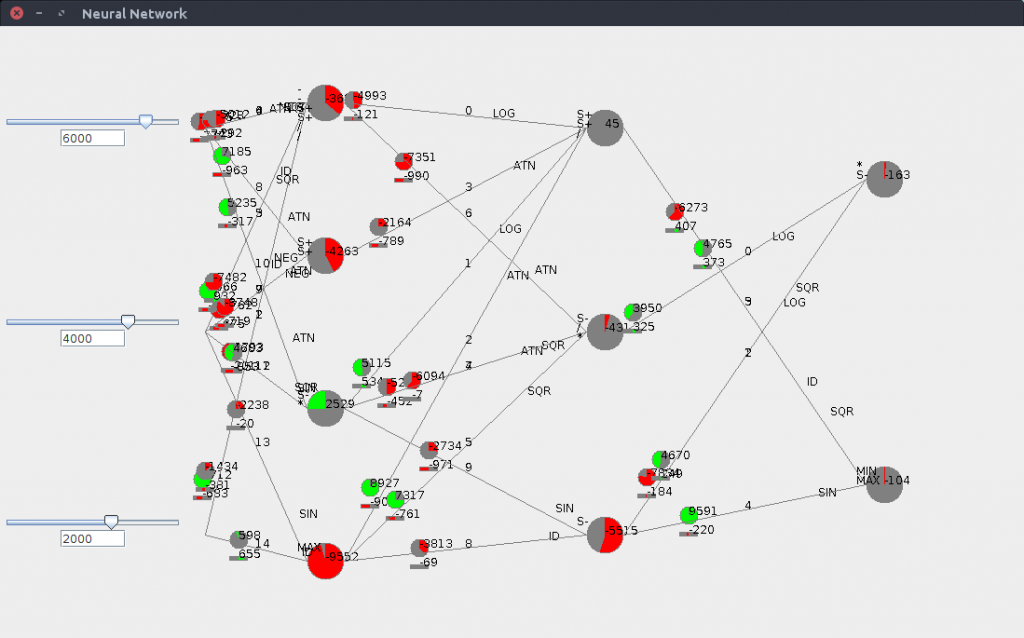
The inputs are on the left, and can be entered either numerically or from sliders, and the outputs are read on the right (this one has only two outputs). The two hidden layers (containing 4 and 3 neurons) are clearly visible. Besides, every link has the offset represented as a bar (red means negative, green means positive, full gray is 0) and the weights are represented as filled circles.
In the next article, we’ll build the genetic algorithm part of the project.
The next post of the series is here.
Welcome to this second part of the GANN-EWN (Genetic Algorithms for Neural Networks applied to the game “Einstein Würfelt Nicht”) series! If you haven’t read it yet, it’s probably time to read the first part.
The game is quite simple: at the beginning of the game every player has 6 pieces labeled from 1 to 6, and every player throws a die at every turn. Depending on the result of the throw, the player may move one or two of his own pieces. The goal is to reach the opposite side of the board (diagonally) or capture all opponent’s pieces.
The rules with the dice are simple as well. If the die corresponds exactly to one of his pieces, he has to play that piece in any direction forward (the three squares: up, up left, or left), like in here where the die shows “5”:

If no piece with the same number are on the board, then one of the two pieces that are the closest to the die can be played. For instance, if the die was “2”, then the “1” and “3” can be played here:

Again, if the die is “3” then on this board the “2” or the “5” can be played:

Note that if there was no “2” on this board, then only the “5” could be played since there is no lower number than “3” on the board.
The first thing to do was to code a simple board implementing the rules of the game, which is quite straightforward. I chose Java, which is probably the programming language I’m most comfortable with, but also for another reason, which I will develop later.
To have something to compare my neural networks to, and also to test my implementation of the EWN Board and game logic, my first first step was to implement a simple (and I can call it quite “naive”) implementation of a player, based on my very limited experience of the game. Remember that I just discovered EWN, so after having a look at some games from the best players, I realized that one common strategy is to “eat up” some of your own pieces early in the game, to give momentum to your remaining pieces. Although this is a “classic” strategy, it does have one drawback: you opponent may be able to take all your remaining pieces and you lose. Nevertheless, I decided to implement this rule, along with a few others. Here is the list of rules that are hard-coded in this first player:
And that’s it!
So yes, this is a very simple player, but one funny fact is that this player beats me consistently! That’s how weak I am at EWN as a player.
But as those rules can have parameters (how far must an adversary piece so that we capture it? etc.), I ran a simple computer simulation using a range of possible parameters (including totally disabling a rule). And those simulation showed me that, by far, the best parameters are:
Of course, every single rule taken on its own may have some exceptions, but my “simple player” doesn’t go that far.
I also created a “random” player which picks moves at random, again to have something to compare to that doesn’t vary much in its crappiness. 🙂 And indeed my simple player was definitely better than the random one, at least.
I published this first player on the littlegolem site, with a different user than my regular user.
This is when I discovered that the site was actually crawling with bots playing EWN! Nice, the challenge was getting interesting! That’s when I met with a German researcher who also wrote a bot to play EWN on littlegolem. He even made part of his PhD on this project, so needless to say that my own simple player was quite ridiculous compared to his, and got a very bad beating!
This is when I realized that EWN is actually a statistics-driven game, since you make a choice depending on the probabilities of the next dice throws. You have a “2” ahead and want to give it momentum to reach the opposite side of the board faster? Capture your own “1”, “3” and possibly “4” and “5” pieces. The enemy has one piece slightly ahead but that piece has a 1/6 chance to be picked by the dice? Just ignore it. But you will capture that piece if it has a 1/2 chance of being played. As the Wikipedia page points out, one of the first approach is to calculate probability tables for each piece to reach the goal. All the dynamics of that game are based on probabilities. Well, almost. So that makes it a very good candidate for a Monte-Carlo type approach.
As a reminder, the general principle behind the Monte-Carlo approach is: “at a given turn, for each possible move play as many random games as possible and play the one that leads to victory more often than the others.”
Brutal. But very effective and the easiest “AI” to program. I guess. At least on a CPU.
So I implemented a simple Monte-Carlo (that I will abbreviate as “MC” now on) algorithm and launched it against my simple player. And sure enough, the MC player won, even if it was just playing 1000 games with random moves to decide which move to pick. And I’m not speaking about a “little better” here. The MC player won almost 70 games out of 100.
Then I thought: picking random moves is not really a likely outcome for a normal game, so the results for the MC player are somehow skewed. What if I use my simple player instead of a random player to play the games?
No surprise, using the simple player within the MC player improved the results against the simple player by quite a bit. But against the random MC player, the difference was not that big, it just improved it slightly, but not really significantly, only by 2.5 to 3% which is not bad but not as much as I would have expected. Note that running this simulation on a CPU is costing a lot of cycles. 1000 games with each roughly 15 to 20 moves. And at each turn, play 1000 games for every possible move (there are 1 to 6 possible moves). That’s a lot of moves to run! I’ve accelerated that to run on a GPU, but that will come later.
And still, the MC player lost to the German PhD’s carefully hand-crafted player. Well if a simple MC approach would do it, that’s what he would have picked in the first place!
This is it for this part. Next, we’ll start building a Neural Network with its associated Genetic Algorithm.
Combining Genetic Algorithms and Neural Networks is an idea that has been troubling my mind for the last 20 years. Unfortunately, life went in the way and I didn’t have a real chance of putting this idea into practice. Neural networks are very often used to do some “classifying” jobs, and they are very good at it. At least they got far beyond what we humans could program ourselves. However, as I have ideas for developing very interesting games, I also had in mind to have an AI play those games, and an AI that would actually learn how to play them, rather than programing it myself. This is exactly what the guys at DeepMind have been doing in the recent years. From Atari games to Go and Chess (and Shogi), they have amazed us all.
As I’m going back to my original interest in AI, I have taken upon myself to build an AI from scratch that would do exactly what I had in mind 20 years ago: learn how to play games.
In the meantime, things in the AI field have evolved. Graphics cards have opened new horizons for training bigger and faster Neural Networks. I have had some graphics cards that I used at some point to mine some cryptocurrencies for fun. Those cards were AMD cards, and they were getting hot very easily (the 7970 was going up to 100 degrees Celsius, I suspect that the fitting of the radiators were poorly made). I set up a watercooling system for the whole miner. Although it was a very interesting experience, it came to an end rather quickly. since ASICs kicked in and rendered graphics cards useless.
At the time, I started a project for handwriting character recognition (more on this project later…), and I used one of those cards to apply some graphics transformations (Hough transform and such). But they also consume a lot of electricity. So, sorry AMD, but I switched to Nvidia (I don’t own any stocks of either of those companies… or any other company, by the way, but I do believe that AMD is seriously losing ground here), which also has some great support with tools to build Neural Networks like TensorFlow.
So I wanted to start with a simple game and a simple goal:
But everything had to start somewhere. And I didn’t want to tackle Chess or Go as my first GANN project. Anyway, the DeepMind guys have done that already!
So I had to aim for something simple for a start, and at the same time some game that I didn’t know well so that I wouldn’t be tempted to direct the algorithm and make “Stockfish for game XXX”. On the same note, another strong criteria was also that it shouldn’t be a game that had been solved by mainstream software, like Chess, Checkers or Reversi/Othello. At the website littlegolem on which I play board games, there are some games that I don’t know well (yet) and also many games for which mainstream software is not really available. One of them is called “Einstein Würfelt Nicht” (which I will call EWN in the future) and is actually a dice game, played on a 5×5 board. When I started this project, I had never played that game but the rules seemed quite simple and I decided to have a go at it. This was of course the first attempt, the first prototype, basically some starting point, but certainly not the end point.
There are also two variants of the game on the site, which would be also nice to tackle. My initial goal there was to defeat human players and become a top player on the site. Note that this particular site is also very flexible with its players, and doesn’t ban anyone. If you don’t like playing against cheaters or robots, then that site is definitely not for you. But personally I learn a lot by playing with any kind of opponent, it doesn’t matter if I win or if I lose.
I will develop that story in the next articles, and I will also post some of the code soon on my gitlab account. However, I will not post the full code, don’t expect to be able to have a running bot that would play for you at EWN from there. But the generic code will be there and will be adaptable to other games as well.
The next part is here.