If you haven’t read the previous parts, you should start at part 1.
Now that we have a Neural Network architecture and a Genetic Algorithm, we can apply them to the game “Einstein Würfelt Nicht”.
The Parameters of the Problem
There are several parameters that need to be addressed first:
- how to feed information to the NN and how to get a result,
- how big should the NN be, how many layers, how many neurons per layer, how many connections between each layer,
- how to tune the parameters for the GA (population size, mutation rate, etc.).
There are some precedents for every of these 3 points (NNs as well as GAs have been studied), but there is no existing answer for this particular set of problems.
Feeding Information to the NN
The answer to the first question seems trivial, but it is actually not. The first answer that comes to mind is “just feed it the board and the die and get the stone that has to be played and the move to be played”.
This is of course a valid answer, but there are many more:
- don’t feed the whole board, but rather the positions of the stones along with the die,
- feed the possible moves instead of the die,
- or you could use the network as a “value network”, in other words let the network evaluate how favorable a certain position is for the current player. In that case, the algorithm has to simulate every possible move and apply the network on every resulting board.
There are many other ways of feeding information, including feeding redundant information. For instance, you could feed the number of stones left for each player in addition to the board: that’s an information which is obviously useful and that the network could directly use rather than having to calculate it again.
Getting the NN’s Result
The Neural Network can be used to gather very different results, also depending on which information it was given as inputs. Here are a few ways that the network can be used:
- the number of the tile to be played along with the move to be played,
- among all the possible moves, get the index of the chosen move,
- return one output number for each tile and each move, and play the tile that has the highest number along with the move that has the highest number,
- if used as a value network, just return one value: the fitness of the current position.
Again, there are many ways of using a neural network to play. We could even use two networks: one to choose the tile to play, and then a second one to choose the move. Whatever we choose, we have to keep in mind two main points here:
- the result can never be an invalid move, which is not always trivial,
- make sure that results cannot be incoherent. For instance, a valid possibility would be to have two integer outputs: one for the tile to play on the board, one for the move to play, each of them being applied the mathematical “mod” to make sure that the results are within range. But then there might be a discrepancy between the chosen tile and the chosen move. Maybe the move made perfect sense with another tile, but not with the one that was eventually selected.
The Size of the Neural Network
I tend to reason in terms of complexity of the game to address this problem. Just think about “if I had to code a perfect player for this game, how many rules and cases would I have to take into account”.
The answer also depends on what you feed the network. If you feed it a lot of redundant information (for instance, feed it the board and the number of remaining tiles for each player), then the network will have to extract less metadata from the board.
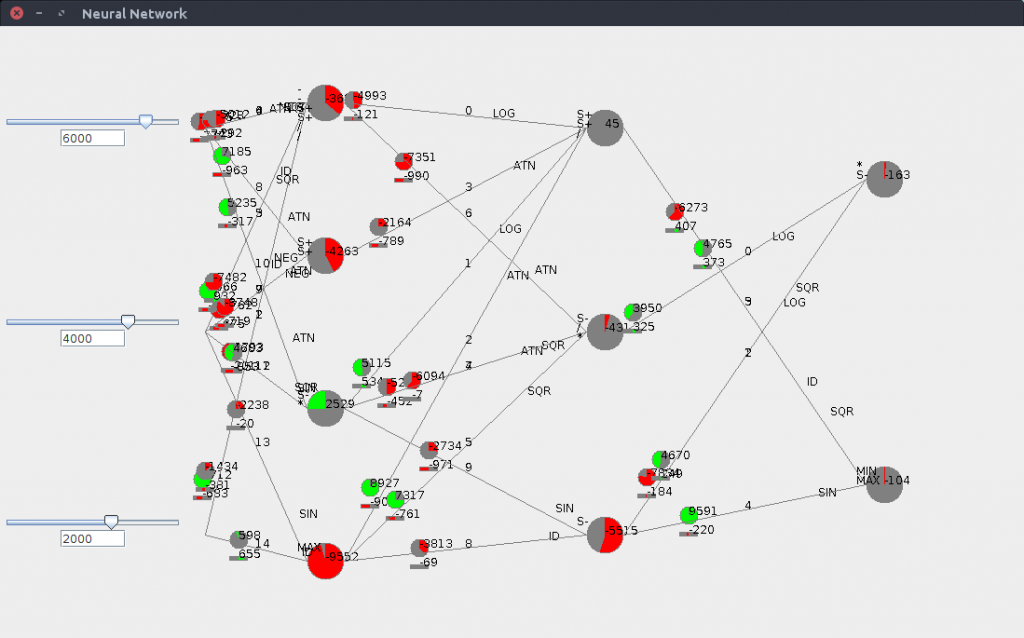
In the case of the game “Einstein Würfelt Nicht”, I chose not to mostly not give any redundant information to the network. Given the size of the board, I believed that a simple network of just a few layers and a couple of hundred neurons would probably do the trick.
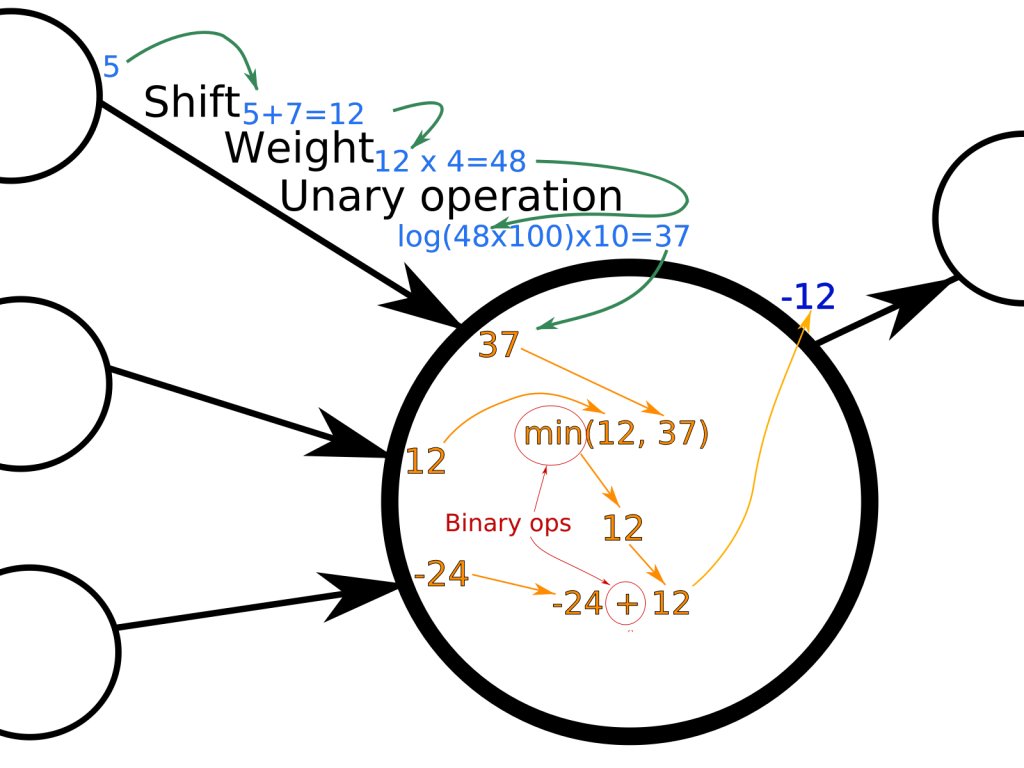
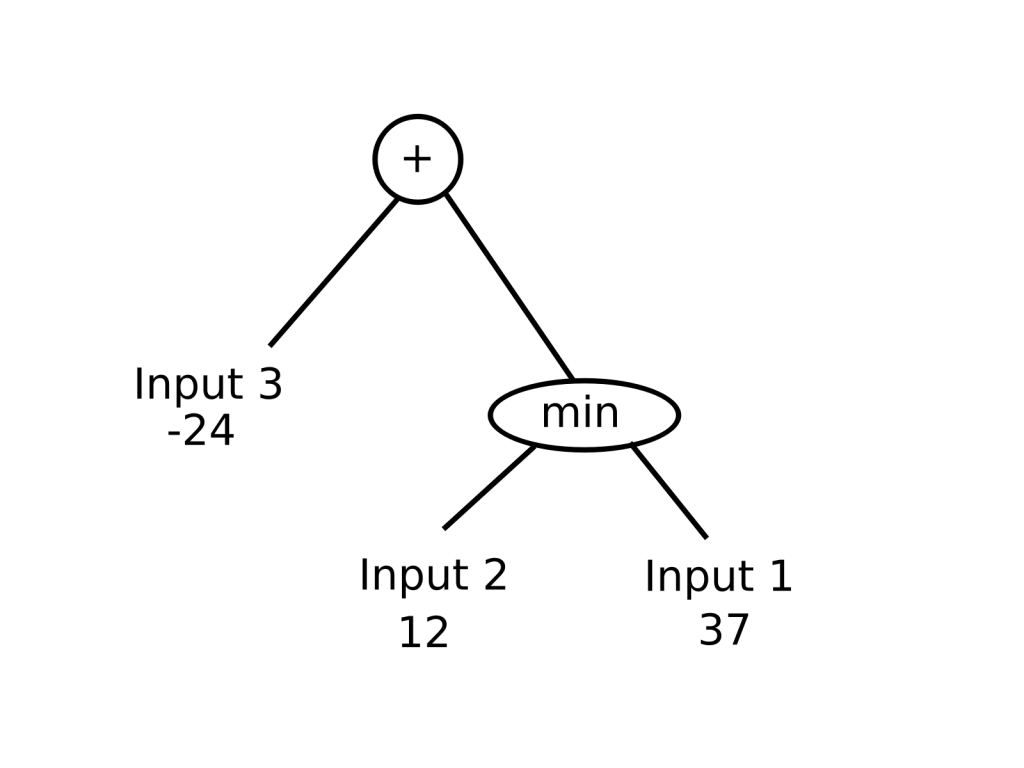
Then comes the number of connections between layers. In order to extract as much information as possible from the board, I believed that a fully connected first layer was needed – although I chose not to enforce it, but I gave a sufficient amount of connections for this to happen. So I started off with a first layer of 20 neurons, along with 500 connections between the board (which is a 25 bytes array, with an additional byte for the die). I have also tried other different variants.
The Parameters of the Genetic Algorithm
Population size, mutation and cross-over rates
I started off with a population of 100 individuals and made some tests with 200. In that population, I chose to keep a fair amount of the best individuals, 10 to 30%, without checking their scores. All the others are discarded and replaced with either new individuals, either top individuals that have been mutated and crossed-over.
As for the mutation rate, I made it randomly chosen between 1/1000 and ten to twenty per 1000. That is to say that to create a mutated individual, 1 to 10/20 random mutations are applied for every 1000 bytes of its DNA. Note that with a network of 10000 elements, that’s just a few mutations in the network. A mutation can be a change in an operation, a connection move or a change in parameters such as weight and offset.
As for the crossover rate, I made it from 0.01% to 1%. As we will see later, it wasn’t that successful in the first versions.
Evaluating players
Another important parameter is the accuracy of the evaluation for every individual. In the case of a game, it can be measured by having this individual play many games against other players. Other players may be other individuals of the population and/or a fixed hard-coded player. The more games are played, the more accurate the rating of a player. And this is getting more and more critical as the player improves: at the beginning, the player just needs to improve very basic skills and moves, it is failing often anyway, so it is easy to tell the difference between a good player and a bad one. As it improves, it becomes more and more difficult to find situations in which players can gain an advantage or make a slight mistake.
In the case of EWN, as it is a highly probabilistic game, the number of matches that are required can grow exponentially. Note that there are even a large number of starting positions: 6! x 6! which is roughly 500 thousand permutations. With symmetries we can remove some of them, but there is still a large number of starting positions despite the very simple placing rules. So even if you play 100.000 games for a player, it is still not covering the wide variety of openings. What if your player handles well those 100.000 openings but is totally lame at playing the rest? Not even mentioning the number of possible positions after a few turns.
A good indicator to check whether we have played enough games to correctly rate players is the “stability” of the ranking of players as we continue playing games. As the rankings stabilize (eg for instance the top player remains at the top for quite a long time) we are getting better and better accuracy.
Individuals selection and breeding
As I developed this and started testing it, I realized that the evolution was going very slowly: new individuals were bad in general, with only a few of them reaching the “elite” of the population. That’s because of the randomness of the alterations. We will see later how I tackled that problem.
As I was going forward in this and observing how slow the process was on a CPU, I also started planning to switch the whole evaluation process to the GPU.